Microsoft Research Asia (MSRA) recently blew everyone away with their results on the ImageNet and COCO datasets. If you haven’t yet seen the work check out the paper here and especially some of the examples in the presentation here (Note: I’ve borrowed some of their figures below). Computer vision has come a long way, color me impressed!
Their basic claim is that a deeper network should in principle be able to learn anything a shallower network can learn: if the additional layers simply performed an identity mapping, the deeper network would be functionally identical to a shallower network. However, they show empirically that increases in network depth beyond a certain point make deeper networks perform worse than shallower networks. Despite modern optimization techniques like batch normalization and Adam, it seems ultra-deep networks with a standard architecture are fundamentally hard to train with gradient methods.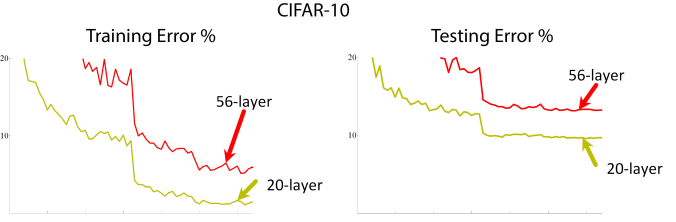 It would seem that for standard architectures and training methods, we’ve passed the point of diminishing returns and started to regress. The theoretical benefits of increased depth, will never be realized unless we do something differently. We must go deeper!
It would seem that for standard architectures and training methods, we’ve passed the point of diminishing returns and started to regress. The theoretical benefits of increased depth, will never be realized unless we do something differently. We must go deeper!
The MSRA paper makes a simple proposal based on their insight that the additional layers in deeper networks need only perform identity transforms to perform as well as shallower networks. Because the deeper networks seem to have a hard time discovering the identity transform on their own, they simply build the identity transform in! The layers in the neural network now learn a “residual” function F(x) to add to the identity transform. To perform an identity transform only, the network only needs to force the weights in F(x) to zero. The basic building block of their Deep Residual Learning network is:

A similar line of reasoning also led to the recently proposed Highway networks. The main difference is that Highway networks have an additional set of weights that control the switching between, or mixing, of x and F(x).
My first reaction to the residual learning framework, was “that’s an interesting hack, I’m amazed it seems to work as well as it does”. Now don’t get me wrong, I love a simple and useful hack (*cough* dropout *cough* batch normalization *cough*) as much as the next neural net aficionado. But on further consideration, it occurred to me there is an interesting way to look at what is going on in the residual learning blocks in terms of theoretical neuroscience.
Below is a cartoon model of some of the basic computations believed to take place within a cortical area of the brain. (A couple examples of research in this area can be found here and here.) The responses of pyramidal cells, the main output cells of cortex (shown as triangles), are determined by their input as well as modulations due locally recurrent interactions with inhibitory cells (shown as circles) and each other. I hope the analogy I’m making to the components of the residual learning block is made clear by the color coding. Basically the initial activation, shown in red and indicated by x, is due to the input. This initial activation triggers the recurrent connections which are a nonlinear function of the initial activation, shown in blue and represented by F(x). The final output, shown in purple, is simply the sum of the input driven activity, x, and the recurrently driven activity, F(x).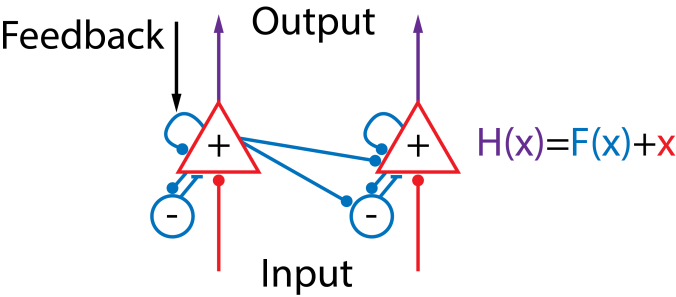 The residual learning blocks can thus be thought of as implementing locally recurrent processing, perhaps analogously to how it happens in the brain! The input to a brain area/residual learning block is processed recurrently before being passed to the next brain area/residual learning block. Obviously, the usual caveats apply: the processing in the brain is dynamic in time and is much more complicated and nonlinear, there is no account of feedback here, etc. However, I think this analogy might be a useful, and biologically plausible, way to understand the success of deep residual learning.
The residual learning blocks can thus be thought of as implementing locally recurrent processing, perhaps analogously to how it happens in the brain! The input to a brain area/residual learning block is processed recurrently before being passed to the next brain area/residual learning block. Obviously, the usual caveats apply: the processing in the brain is dynamic in time and is much more complicated and nonlinear, there is no account of feedback here, etc. However, I think this analogy might be a useful, and biologically plausible, way to understand the success of deep residual learning.

Thanks for the comment Ben! With regard to your question about whether the brain uses a very deep algorithm, well it can’t be that deep, and no where near 152 layers. It would simply take too long for a signal to flow through that many synapses. I also think a direct mapping between layers of a convnet and the brain has always been dicey, and now with these ultra deep networks is clearly impossible. Perhaps these ultra deep networks are doing something like unrolling the recurrent interactions between brain areas into a feedforward chain, and performing operations sequentially that happen in parallel in the brain. Also, the residual learning framework gives the network a lot of freedom to spread the necessary nonlinearities across depth so that each individual layer doesn’t have to do anything too complex.
Regarding the gains only on very deep networks, from their presentation, they seemed to see gains even at the lowest number of layers tested, 18 I believe, but I haven’t tested anything smaller myself.
Regarding replacing the identity with a linear transform, i.e. H(X) = F(X) + WX, they actually did that on modules where the output layer was a different dimensionality from the input,. They also tested a variant “ResNet-34 C” where all the identity transforms were replaced with projections, which actually performed a little bit better than the model with identity transforms, “ResNet-34 B”. Their 152 layer model however was based on “ResNet-34 B” because the identity transform did almost as well and has a lot fewer parameters. I do think something like the sequence of events you describe is going on, and that convnets might be approximating that process in a feedforward manner.
I’m not sure I have a detailed enough hypothesis to test in vivo, but I would love to hear ideas.
Cheers!
LikeLike
What a great first post! Very efficient and thought-provoking. The success of residual learning also got me thinking about whether the brain is doing something similar. I think your idea of implementation through local recurrent connections is plausible and really cool! I am really fascinated by this idea, and I have a few questions for you:
Do you think the brain is really using a very deep algorithm? Most studies I’ve seen relating ANNs to brains map each layer to a major visual processing area e.g. V1, V2. Do you think the brain’s image recognition algorithm is far more layered than these studies and anatomical studies would suggest? It seems like residual learning would only provide substantial benefits in the regime of very deep algorithms.
Do you think the feedforward connections are really identity? Generalizing the idea of residual learning, you might want to constrain the forward transformation more loosely. Instead of constraining them to be the identity matrix, you might constrain them to be linear and non-linear transformation could be learned by recurrent connections. Really you could impose any constraint that would make the feedforward connections easier to learn. In the brain, this would have the benefit of giving you an approximate picture right away and having that picture refined by recurrent connections. The speed with which we are able to process images suggests something like this might going on.
Finally, I would be really excited to see this tested in vivo. do you have any ideas for how you might do that? What would the corresponding null hypothesis be?
LikeLike